import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset, random_split
from torchvision.transforms import ToTensor, Resize, Compose
from torchvision.utils import save_image
from PIL import Image
import os
from glob import glob
import cv2
import numpy as np
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torchvision.datasets import ImageFolder
import os
import timeSelf Supervised Learning on CIFAR10
Overview
Initially we train EfficientNet model on 5% of the data and then test it on 50% of the test data. Then we create the jigsaw pre training dataset on 45% of the images. Then the pretrained model is fine tuned on the 5% of images and tested on 50% of the data. Additional experiments like using pretrained weights for EfficientNet and varying hyperparameters have been carried out.
Import Libraries
Preparing DataLoaders
from torchvision.datasets import CIFAR10
transform = Compose([
# Resize images to 33x33 to make it divisible by 3 for the later jigsaw task.
Resize((33, 33)),
ToTensor()
])
# Load CIFAR-10 dataset
dataset = CIFAR10(root='./data', train=True, download=True,
transform=transform)
# Split dataset
train_size = int(0.05 * len(dataset))
pretrain_size = int(0.45 * len(dataset))
test_size = len(dataset) - train_size - pretrain_size
train_dataset, pretrain_dataset, test_dataset = random_split(
dataset, [train_size, pretrain_size, test_size])
# Create data loaders
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
pretrain_loader = DataLoader(pretrain_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)Files already downloaded and verifiedInitial training on 5% of the data
Initially using the efficient net model without pretraining.
from torchvision import models
model = models.efficientnet_b0(pretrained=False)
num_ftrs = model.classifier[1].in_features
model.classifier[1] = nn.Linear(num_ftrs, 10)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)/usr/lib/python3/dist-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/usr/lib/python3/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)# Loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# train on only 5% of the data
loss_list = []
lr = []
for epoch in range(25): # loop over the dataset multiple times
scheduler.step()
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, targets = data
inputs = inputs.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
lr.append(scheduler.get_lr()[0])
running_loss += loss.item()
if i % 10 == 9: # print every 10 mini-batches
print('[%d, %5d] loss: %.3f, lr: %.6f' %
(epoch + 1, i + 1, running_loss / 10, scheduler.get_lr()[0]))
# append avg running loss every 10 epochs
loss_list.append(running_loss/10)
running_loss = 0.0plt.subplot(2, 1, 1)
plt.plot(loss_list, label='Training Loss')
plt.title('Training Loss over Batches')
plt.xlabel('Batch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(lr, label='Learning Rate', color='r')
plt.title('Learning Rate over Batches')
plt.xlabel('Batch')
plt.ylabel('Learning Rate')
plt.legend()
plt.tight_layout()
plt.show()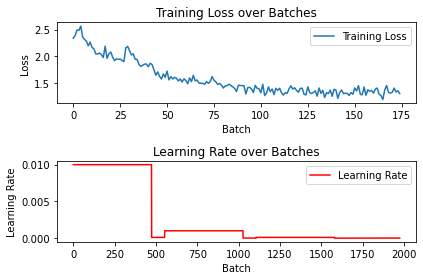
# save the model state dict
torch.save(model.state_dict(),
'./cifar10_5percent_scheduler_pretrained_false.pth')Using a pretrained (on imagenet) efficienet model
from torchvision import models
model = models.efficientnet_b0(pretrained=True)
num_ftrs = model.classifier[1].in_features
model.classifier[1] = nn.Linear(num_ftrs, 10)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# Loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)/usr/lib/python3/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=EfficientNet_B0_Weights.IMAGENET1K_V1`. You can also use `weights=EfficientNet_B0_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Downloading: "https://download.pytorch.org/models/efficientnet_b0_rwightman-3dd342df.pth" to /home/deus/.cache/torch/hub/checkpoints/efficientnet_b0_rwightman-3dd342df.pth
100%|██████████| 20.5M/20.5M [00:01<00:00, 14.2MB/s]# train on only 5% of the data
loss_list = []
lr = []
for epoch in range(25): # loop over the dataset multiple times
scheduler.step()
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, targets = data
inputs = inputs.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
lr.append(scheduler.get_lr()[0])
running_loss += loss.item()
if i % 10 == 9: # print every 10 mini-batches
print('[%d, %5d] loss: %.3f, lr: %.6f' %
(epoch + 1, i + 1, running_loss / 10, scheduler.get_lr()[0]))
loss_list.append(running_loss/10)
running_loss = 0.0plt.subplot(2, 1, 1)
plt.plot(loss_list, label='Training Loss')
plt.title('Training Loss over Batches')
plt.xlabel('Batch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(lr, label='Learning Rate', color='r')
plt.title('Learning Rate over Batches')
plt.xlabel('Batch')
plt.ylabel('Learning Rate')
plt.legend()
plt.tight_layout()
plt.show()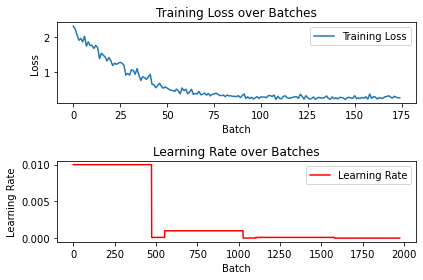
# save the model state dict
torch.save(model.state_dict(),
'./cifar10_5percent_scheduler_pretrained_true.pth')Using adam optimiser (an attempt at hyperparameter tuning
from torchvision import models
model = models.efficientnet_b0(pretrained=True)
num_ftrs = model.classifier[1].in_features
model.classifier[1] = nn.Linear(num_ftrs, 10)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)import torch.optim as optim
# Loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01) # Using Adam optimizer
num_epochs = 25
loss_list = []
# Training loop
for epoch in range(num_epochs):
running_loss = 0.0
for i, (inputs, targets) in enumerate(train_loader):
# inputs = reassemble_patches(inputs, grid_size=3)
inputs, targets = inputs.to(device), targets.to(device)
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 10 == 9: # print every 10 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 10))
loss_list.append(running_loss/10)
running_loss = 0.0plt.subplot(2, 1, 1)
plt.plot(loss_list, label='Training Loss')
plt.title('Training Loss over Batches')
plt.xlabel('Batch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(lr, label='Learning Rate', color='r')
plt.title('Learning Rate over Batches')
plt.xlabel('Batch')
plt.ylabel('Learning Rate')
plt.legend()
plt.tight_layout()
plt.show()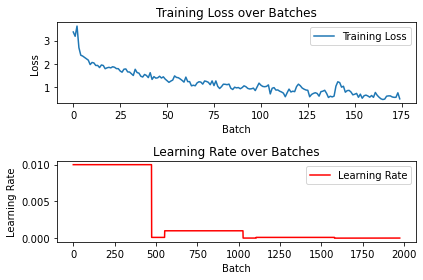
# save the model state dict
torch.save(model.state_dict(), './cifar10_5percent_adam_pretrained_true.pth')Image Jigsaw Puzzle Pretraining
from itertools import permutations
from torchvision.transforms import functional as F
def extract_patches(image, grid_size=3):
patch_size = image.size(1) // grid_size
patches = [F.crop(image, i, j, patch_size, patch_size)
for i in range(0, image.size(1), patch_size)
for j in range(0, image.size(2), patch_size)]
return patches
def apply_permutation(patches, perm):
return [patches[i] for i in perm]
# Example permutation generation (100 permutations)
num_permutations = 100
all_perms = np.array(list(permutations(range(9))))
selected_perms = all_perms[np.random.choice(
len(all_perms), num_permutations, replace=False)]from torch.utils.data import Dataset
class JigsawPuzzleDataset(Dataset):
def __init__(self, dataset, permutations):
self.dataset = dataset
self.permutations = permutations
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
image, _ = self.dataset[idx]
perm_idx = np.random.choice(len(self.permutations))
perm = self.permutations[perm_idx]
shuffled_patches = apply_permutation(extract_patches(image), perm)
# Convert list of patches to tensor
shuffled_image = torch.stack(shuffled_patches)
return shuffled_image, perm_idx
# Example usage
pretrain_dataset = JigsawPuzzleDataset(pretrain_dataset, selected_perms)import matplotlib.pyplot as plt
import numpy as np
import torchvision.transforms as transforms
def visualize_jigsaw(original_image, permuted_patches, grid_size=3):
"""
Visualize the original and permuted image side by side.
Args:
original_image (Tensor): The original image tensor.
permuted_patches (Tensor): The permuted patches tensor.
grid_size (int): The size of the grid to divide the image into.
"""
# Convert tensors to numpy arrays
original_image = original_image.permute(1, 2, 0).numpy()
# Reconstruct permuted image from patches
patch_size = original_image.shape[0] // grid_size
permuted_image = permuted_patches.view(
grid_size, grid_size, 3, patch_size, patch_size)
permuted_image = permuted_image.permute(0, 3, 1, 4, 2).contiguous()
permuted_image = permuted_image.view(
grid_size * patch_size, grid_size * patch_size, 3)
# Plotting
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].imshow(original_image)
axes[0].set_title("Original Image")
axes[0].axis('off')
axes[1].imshow(permuted_image)
axes[1].set_title("Permuted Image")
axes[1].axis('off')
plt.show()
# Example usage
# Assuming 'pretrain_jigsaw_dataset' is the JigsawPuzzleDataset instance
original_image, _ = pretrain_dataset.dataset[0] # Get an original image
permuted_image, _ = pretrain_dataset[0] # Get a permuted image
print(_)
visualize_jigsaw(original_image, permuted_image)13
Using an EfficientNet model pretrained on ImageNet
from torchvision import models
# Load EfficientNet model
model = models.efficientnet_b0(pretrained=True)
# Modify the last layer for permutation prediction
num_ftrs = model.classifier[1].in_features
num_permutations = 100 # Assuming 100 permutations
model.classifier[1] = nn.Linear(num_ftrs, num_permutations)
pretrain_loader = DataLoader(pretrain_dataset, batch_size=32, shuffle=True)
# Move the model to GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)def reassemble_patches(patches, grid_size=3):
"""
Reassemble the shuffled patches into a single image tensor.
Converts 5d to 4d vector
"""
batch_size, num_patches, channels, patch_height, patch_width = patches.shape
patches = patches.view(batch_size, grid_size, grid_size,
channels, patch_height, patch_width)
patches = patches.permute(0, 1, 4, 2, 5, 3).contiguous()
patches = patches.view(batch_size, grid_size *
patch_height, grid_size * patch_width, channels)
# Rearrange axes to [batch_size, channels, height, width]
patches = patches.permute(0, 3, 1, 2)
return patchesimport torch.optim as optim
# Loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01) # Using Adam optimizer
num_epochs = 10
loss_list = []
lr = []
# Training loop
for epoch in range(num_epochs):
running_loss = 0.0
for i, (inputs, targets) in enumerate(pretrain_loader):
inputs = reassemble_patches(inputs, grid_size=3)
inputs, targets = inputs.to(device), targets.to(device)
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr.append(scheduler.get_lr()[0])
running_loss += loss.item()
if i % 10 == 9: # print every 10 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 10))
loss_list.append(running_loss/10)
running_loss = 0.0plt.subplot(2, 1, 1)
plt.plot(loss_list, label='Training Loss')
plt.title('Training Loss over Batches')
plt.xlabel('Batch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(lr, label='Learning Rate', color='r')
plt.title('Learning Rate over Batches')
plt.xlabel('Batch')
plt.ylabel('Learning Rate')
plt.legend()
plt.tight_layout()
plt.show()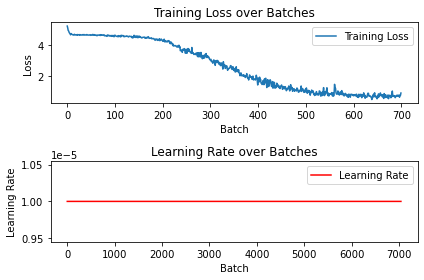
from torchvision import models
import torch.nn as nn
import torch.optim as optim
import torch
# Get the number of input features to the last layer
num_ftrs = model.classifier[1].in_features
# Reset the last layer for CIFAR-10 classification (10 classes)
model.classifier[1] = nn.Linear(num_ftrs, 10)
# Move the model to GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# Loss function and optimizer for fine-tuning
criterion = nn.CrossEntropyLoss()
# Using Adam optimizer, LR can be adjusted as needed
optimizer = optim.Adam(model.parameters(), lr=0.01)
# Number of epochs for fine-tuning
num_fine_tune_epochs = 25
loss_list = []
# Fine-tuning training loop
for epoch in range(num_fine_tune_epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# Get the inputs and labels
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward and optimize
loss.backward()
optimizer.step()
# Print statistics
running_loss += loss.item()
if i % 10 == 9: # print every 10 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 10))
loss_list.append(running_loss/10)
running_loss = 0.0plt.subplot(2, 1, 1)
plt.plot(loss_list, label='Training Loss')
plt.title('Training Loss over Batches')
plt.xlabel('Batch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()
torch.save(model.state_dict(), './pretrained.pth')Using an EfficientNet model without pretraining on imagenet
from torchvision import models
model = models.efficientnet_b0(pretrained=False)
num_ftrs = model.classifier[1].in_features
num_permutations = 100 # Assuming 100 permutations
model.classifier[1] = nn.Linear(num_ftrs, num_permutations)
pretrain_loader = DataLoader(pretrain_dataset, batch_size=32, shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)import torch.optim as optim
# Loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01) # Using Adam optimizer
num_epochs = 10
loss_list = []
# Training loop
for epoch in range(num_epochs):
running_loss = 0.0
for i, (inputs, targets) in enumerate(pretrain_loader):
inputs = reassemble_patches(inputs, grid_size=3)
inputs, targets = inputs.to(device), targets.to(device)
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 10 == 9: # print every 10 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 10))
loss_list.append(running_loss/10)
running_loss = 0.0plt.subplot(2, 1, 1)
plt.plot(loss_list, label='Training Loss')
plt.title('Training Loss over Batches')
plt.xlabel('Batch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(lr, label='Learning Rate', color='r')
plt.title('Learning Rate over Batches')
plt.xlabel('Batch')
plt.ylabel('Learning Rate')
plt.legend()
plt.tight_layout()
plt.show()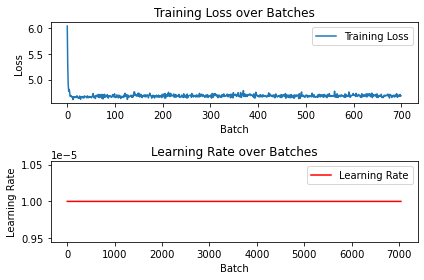
An interesting observation is that there is hardly any drop in training loss as compared to the one with transferred weights, indicating the neural network doesn’t understand image feratures that well yet.
from torchvision import models
import torch.nn as nn
import torch.optim as optim
import torch
# Get the number of input features to the last layer
num_ftrs = model.classifier[1].in_features
# Reset the last layer for CIFAR-10 classification (10 classes)
model.classifier[1] = nn.Linear(num_ftrs, 10)
# Move the model to GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# Loss function and optimizer for fine-tuning
criterion = nn.CrossEntropyLoss()
# Using Adam optimizer, LR can be adjusted as needed
optimizer = optim.Adam(model.parameters(), lr=0.01)
# Number of epochs for fine-tuning
num_fine_tune_epochs = 25
loss_list = []
# Fine-tuning training loop
for epoch in range(num_fine_tune_epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# Get the inputs and labels
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward and optimize
loss.backward()
optimizer.step()
# Print statistics
running_loss += loss.item()
if i % 10 == 9: # print every 10 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 10))
loss_list.append(running_loss/10)
running_loss = 0.0plt.subplot(2, 1, 1)
plt.plot(loss_list, label='Training Loss')
plt.title('Training Loss over Batches')
plt.xlabel('Batch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()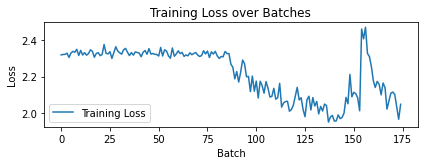
torch.save(model.state_dict(), './notpretrained.pth')import torch
import torch.nn as nn
from torchvision import models
from torch.utils.data import DataLoader
# Define the test_model function
def test_model(model, dataloader, device):
model.eval() # Set the model to evaluation mode
total_correct = 0
total_samples = 0
with torch.no_grad():
for inputs, labels in dataloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
total_samples += labels.size(0)
total_correct += (predicted == labels).sum().item()
accuracy = total_correct / total_samples
return accuracy
# List of model file paths
model_paths = [
'./cifar10_5percent_scheduler_pretrained_false.pth',
'./cifar10_5percent_adam_pretrained_true.pth',
'./cifar10_5percent_scheduler_pretrained_true.pth',
'./notpretrained.pth',
'./pretrained.pth'
]
# Loop through each model
for model_path in model_paths:
# Load the EfficientNet-B0 model
model = models.efficientnet_b0(pretrained=False)
# Modify the classifier for CIFAR-10
num_ftrs = model.classifier[1].in_features
model.classifier[1] = nn.Linear(num_ftrs, 10)
# Load the model weights
model.load_state_dict(torch.load(model_path))
# Move the model to the device (e.g., GPU if available)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# Test the model
accuracy = test_model(model, test_loader, device)
# Print or store the accuracy for this model
print(f'Model: {model_path}, Accuracy: {accuracy*100:.2f}%')Model: ./cifar10_5percent_scheduler_pretrained_false.pth, Accuracy: 39.82%
Model: ./cifar10_5percent_adam_pretrained_true.pth, Accuracy: 50.45%
Model: ./cifar10_5percent_scheduler_pretrained_true.pth, Accuracy: 63.28%
Model: ./notpretrained.pth, Accuracy: 17.29%
Model: ./pretrained.pth, Accuracy: 46.72%Observations: * For training on 5% of the dataset best results are achieved when using pretrained model on imagenet that is 63% and 40% if not prior pretraining is done. * After traning on jigsaw images and then finetuning the best accuracy is 48%. This model uses transferred weights from a pretrained efficientnet on imagenet. The one without any transferred weights gets an accuracy of 34%. * Both the techniques achieve well over the baseline accuracy of 10%(random guessing).
Proposed Solutions to increase accuracy: By using the gap trick, we pad the input disordered images with zeros to the size of original images. Adopting the gap trick can discourage all the jigsaw puzzle solvers mentioned above from learning lowlevel statistics, and encourage the learning of high-level visuospatial representations of objects.
Data Augmentation can help generalising more and improve the self supervised learning.