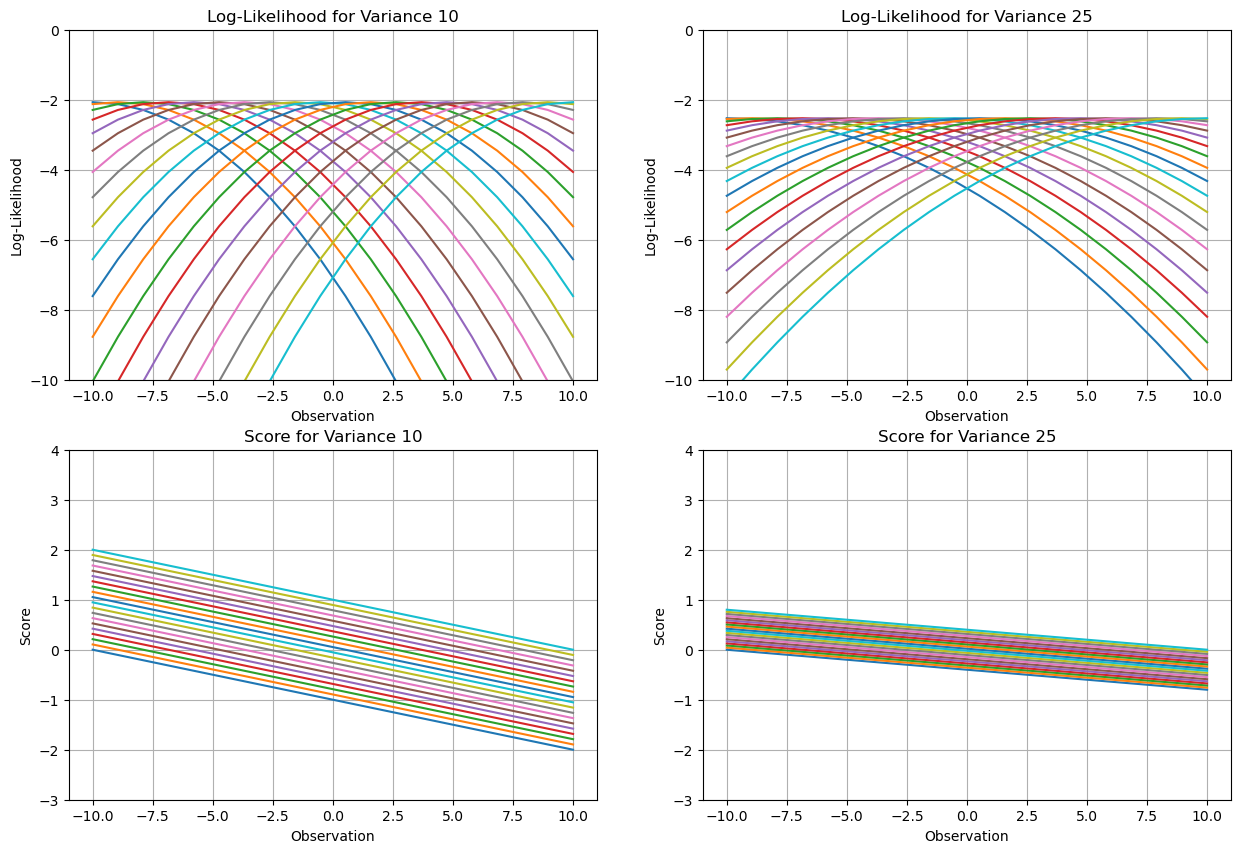
import numpy as np
import matplotlib.pyplot as plt
range_min = -10
range_max = 10
num_points = 20
x_values = np.linspace(range_min, range_max, num_points)
variance1 = 10
variance2 = 25
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 10))
for i, x in enumerate(x_values):
log_likelihood1 = -0.5 * \
np.log(2 * np.pi * variance1) - ((x - x_values) ** 2) / (2 * variance1)
log_likelihood2 = -0.5 * \
np.log(2 * np.pi * variance2) - ((x - x_values) ** 2) / (2 * variance2)
score1 = (x - x_values) / variance1
score2 = (x - x_values) / variance2
ax1.plot(x_values, log_likelihood1, label=f"Observation Point {i+1}")
ax2.plot(x_values, log_likelihood2, label=f"Observation Point {i+1}")
ax3.plot(x_values, score1, label=f"Observation Point {i+1}")
ax4.plot(x_values, score2, label=f"Observation Point {i+1}")
ax1.set_xlabel("Observation")
ax1.set_ylabel("Log-Likelihood")
ax1.set_title(f"Log-Likelihood for Variance {variance1}")
ax1.grid()
ax1.set_ylim([-10, 0]) # set y-limits
ax2.set_xlabel("Observation")
ax2.set_ylabel("Log-Likelihood")
ax2.set_title(f"Log-Likelihood for Variance {variance2}")
ax2.grid()
ax2.set_ylim([-10, 0]) # set y-limits
ax3.set_xlabel("Observation")
ax3.set_ylabel("Score")
ax3.set_title(f"Score for Variance {variance1}")
ax3.grid()
ax3.set_ylim([-3, 4])
ax4.set_xlabel("Observation")
ax4.set_ylabel("Score")
ax4.set_title(f"Score for Variance {variance2}")
ax4.grid()
ax4.set_ylim([-3, 4])
plt.show()